Dify 工作流引擎处理流程源码解析_03_AnswerStreamProfessor篇 根据前面两小节的认识,可以发现 dify 的处理流程大概是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 workflowAppRunner.run() -> workflow_entry.run() -> GraphEngine.run() { if 流程类型 is CHAT: 使用AnswerStreamProcessor else: 使用EndStreamProcessor Then: while True { 1. 判断最大执行step是否达到限制 2. 判断是否超时 3. 初始化节点状态 4. 运行单个节点(所有节点的信息存在map中,通过node_id取信息) 5. 通过edge_map(边信息)找到下一个节点 6. 循环1 ~5 步的步骤,直到整个graph执行完毕 } } <- <- WorkflowBasedAppRunner._handle_event(workflow_entry, event) -> self.queue_manager.publish(event, PublishFrom.APPLICATION_MANAGER)
当使用 AnswerStreamProcessor 的时候,会启动一个异步线程(generate_task_pipeline.py),这个线程负责持续监听一个内置的消息队列。
每次 LLM_Node 输出的时候,会同时输出两个类型的事件:QueueTextChunkEvent和RunStreamChunkEvent,其中RunStreamChunkEvent这个由直接回复节点捕捉并累加,(也就是说直接回复节点本身不具备流式输出的功能);而QueueTextChunkEvent会被消息队列接收并流式输出。
于是我就开始调试 graph_engine.run()这个方法,我发现了一个非常有意思的情况,开始结点执行完毕之后还是正常的,但是执行到大模型节点的时候,哦搜敖德萨这几个字先于流式结果输出出来,或者说,我感觉这几个字在还没走到 llm 节点之后就已经输出出来了。
可是在调试的时候又遇到了问题,因为 graph_engine.run 本质上就是按顺序执行每个节点的 node.run,进而执行每个节点的 _run,但是我执行 llm_node 这个节点的时候发现刚好执行到_invoke_llm 这个方法之后出现了哦搜敖德萨。可是这里不应该是直接调用大模型吗?而且为什么会在流式之前出现所谓的 “哦搜敖德萨”?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class LLMNode (BaseNode[LLMNodeData]): _node_data_cls = LLMNodeData _node_type = NodeType.LLM def _run (self ) -> Generator[NodeEvent | InNodeEvent, None , None ]: node_inputs: Optional [dict [str , Any ]] = None process_data = None try : self .node_data.prompt_template = self ._transform_chat_messages(self .node_data.prompt_template) inputs = self ._fetch_inputs(node_data=self .node_data) generator = self ._invoke_llm( node_data_model=self .node_data.model, model_instance=model_instance, prompt_messages=prompt_messages, stop=stop, )
对这个_invoke_llm 方法进行单步调试之后我发现有个奇怪的地方,执行 db.session.close() 之后会进入到 WorkflowAppGenerateTaskPipeline 中 ,这个类的作用就是记录工作流的状态,读取消息队列的内容返回给前端。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def _invoke_llm ( self, node_data_model: ModelConfig, model_instance: ModelInstance, prompt_messages: Sequence [PromptMessage], stop: Optional [Sequence [str ]] = None , ) -> Generator[NodeEvent, None , None ]: db.session.close() invoke_result = model_instance.invoke_llm( prompt_messages=prompt_messages, model_parameters=node_data_model.completion_params, stop=stop, stream=True , user=self .user_id, ) return self ._handle_invoke_result(invoke_result=invoke_result) class AdvancedChatAppGenerateTaskPipeline : """ AdvancedChatAppGenerateTaskPipeline is a class that generate stream output and state management for Application. """
我先是尝试在 invoke_llm 那个函数尝试单步调试,但是调到 db.session.close 感觉已经到极限了,这里最多就只能看到 taskpipeline 会从消息队列中取消息并抛出,可是这个消息是什么时候放在队列中的呢? ,这个问题显然更加重要。
于是看了眼调试窗口的堆栈,发现最高层也就是 workflow_entry 中的 handle_event 了,我在这里打断点调试,终于是能在放入消息队列之前拦截到这个消息。但是仔细看看这个 event 会发现一个很有意思的情况,这个哦搜敖德萨明明是在直接回复节点里的,可是这里的 node_data 却是开始节点的信息。那么也就是说,其实在走到 llm 节点之前这个消息就已经放在消息队列里了 ,这样一来刚才的推断也符合逻辑了。
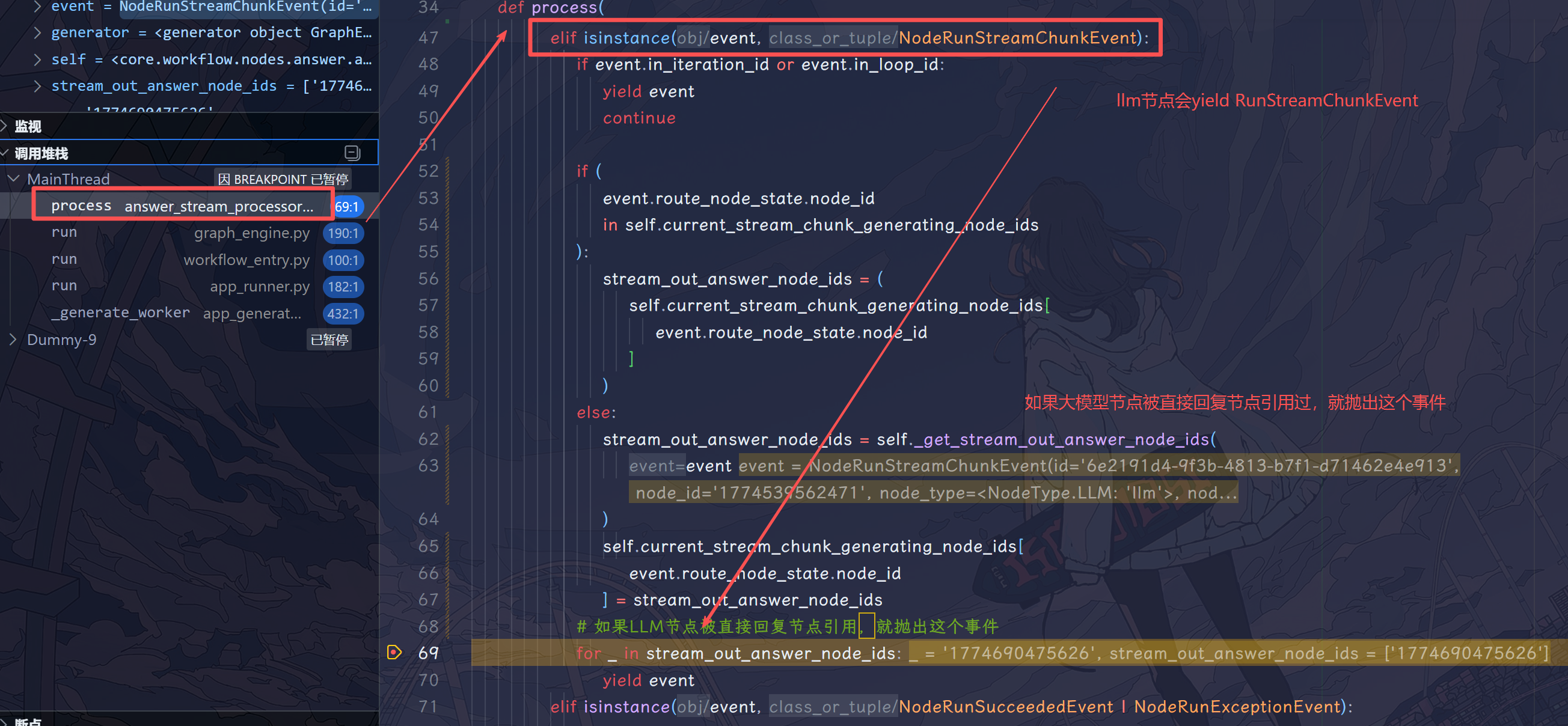
调试 graph_engine.run 没看出啥,只能抱着试一试的心态单步调试 AnswerStreamProfessor 了,没想到还真发现了源头处,就是 AnswerStreamProfessor.generate_stream_outputs_when_node_finished 这个方法。
可以看下面这段代码,这个方法是在每个节点成功执行之后触发的,这里的逻辑是对于每个节点,在执行成功之后就检查节点之后是否有直接回复节点。刚才说过,直接回复节点中对文本和引用变量进行了分块,这里就按分块顺序遍历,如果是文本直接抛出;如果是变量先从 variable_pool 获取,如果获取不到就终止循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 def _generate_stream_outputs_when_node_finished ( self, event: NodeRunSucceededEvent None , None ]: """ Generate stream outputs. :param event: node run succeeded event :return: """ for answer_node_id, position in self .route_position.items(): if event.route_node_state.node_id != answer_node_id and ( answer_node_id not in self .rest_node_ids or not all ( dep_id not in self .rest_node_ids for dep_id in self .generate_routes.answer_dependencies[answer_node_id] ) ): continue route_position = self .route_position[answer_node_id] route_chunks = self .generate_routes.answer_generate_route[answer_node_id][route_position:] for route_chunk in route_chunks: if route_chunk.type == GenerateRouteChunk.ChunkType.TEXT: route_chunk = cast(TextGenerateRouteChunk, route_chunk) yield NodeRunStreamChunkEvent( id =event.id , node_id=event.node_id, node_type=event.node_type, node_data=event.node_data, chunk_content=route_chunk.text, route_node_state=event.route_node_state, parallel_id=event.parallel_id, parallel_start_node_id=event.parallel_start_node_id, from_variable_selector=[answer_node_id, "answer" ], ) else : route_chunk = cast(VarGenerateRouteChunk, route_chunk) value_selector = route_chunk.value_selector if not value_selector: break value = self .variable_pool.get(value_selector) if value is None : break text = value.markdown if text: yield NodeRunStreamChunkEvent( id =event.id , node_id=event.node_id, node_type=event.node_type, node_data=event.node_data, chunk_content=text, from_variable_selector=list (value_selector), route_node_state=event.route_node_state, parallel_id=event.parallel_id, parallel_start_node_id=event.parallel_start_node_id, ) self .route_position[answer_node_id] += 1
那么这样的话,还有一个新的问题,对于刚才的哦搜敖德萨它是一个静态变量嘛,在_generate_stream_outputs_when_node_finished这个方法里直接 yield 出去是可以的,但是大模型不是流式输出的吗?直接回复节点引用该变量之后为什么就能够流式输出?
经过调试,可以发现一个有趣的现象,如果使用了直接回复节点,事件记录会有 RunStreamChunkEvent 和 QueueTextChunkEvent两种事件;如果没有的话,就只有RunStreamChunkEvent这一种事件。
谜底还是在 AnswerStreamProcessor 中,在 02 小节 Graph 篇中,我提到 graph.init 会解析出每个节点与其最近的直接回复节点的关联关系,这里从堆栈信息可以看出,llm_node yield 的 NodeRunStreamChunkEvent 还是会在AnswerStreamProcessor.process.中解析,如果又被 ==“最近的”==直接回复节点引用(get_stream_out_answer_node_ids 方法判断),那么就将此时间抛出,这样就能送到消息队列里。
下面为了更好理解这几节内容,给出几个案例判断一下模型节点输出的内容能否流式输出。
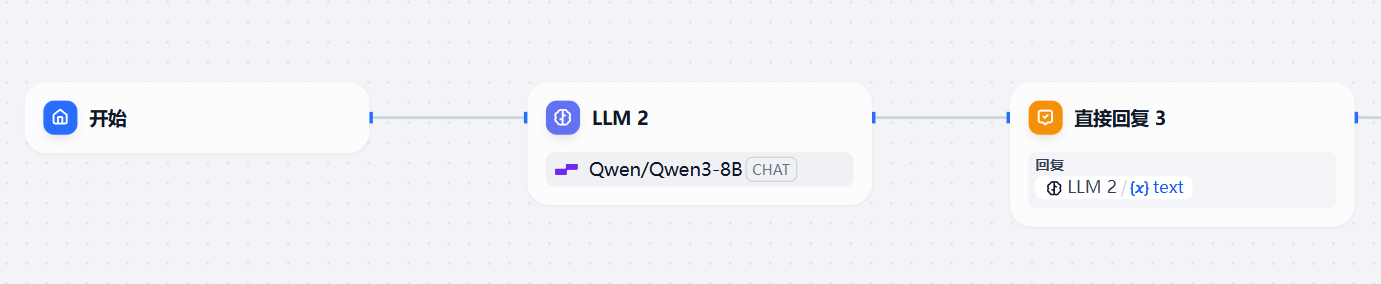
可以流式输出。
答案是可以流式输出,但只有“直接回复 3”可以流式输出。因为根据上一小节,直接回复 3 的上游节点才有 LLM2,直接回复 2 的上游节点在直接回复 3 就会 break(因为属于直接回复类型)。所以 LLM2 的内容直接回复 2 捕捉不到。
不能流式输出。因为直接回复节点看的是 最近 而不是 是否引用 。直接回复 2 虽然引用了 LLM2 输出变量,但是由于 LLM2 不是其上游节点,所以 LLM2 在 AnswerStreamProcessor.process 中只能拿到直接回复 3。
Q: 两个直接回复节点的执行顺序?
不能流式输出。因为上游至条件节点也会 break,所以 LLM2 不是直接回复 2 的上游节点。