
Dify 工作流引擎处理流程源码解析_01_基础结构篇
注:当前研究的 dify 版本为 0.19.1
正好最近和小组长一起在尝试修改 dify 的后台代码,希望可以将“工作流工具”改成流式输出的格式,不过任何事都得一步步来,这两天先看了一下 dify 里最核心的部分:GraphEngine,正好记录一下阅读完源码之后的一点理解。
1. 简单梳理 Workflow 部分源码结构
按照 dify 的 Readme 文件将后端服务跑起来之后,我先根据前端 F12 窗口中的接口地址定位到后台接口位置,打好断点加上查看堆栈信息,可以确定工作流服务的代码都在services\app_generate_service.py这一层。在AppGenerateService.generate这个静态方法中,可以看到对于工作流和 chatflow,使用的 generator 有所不同: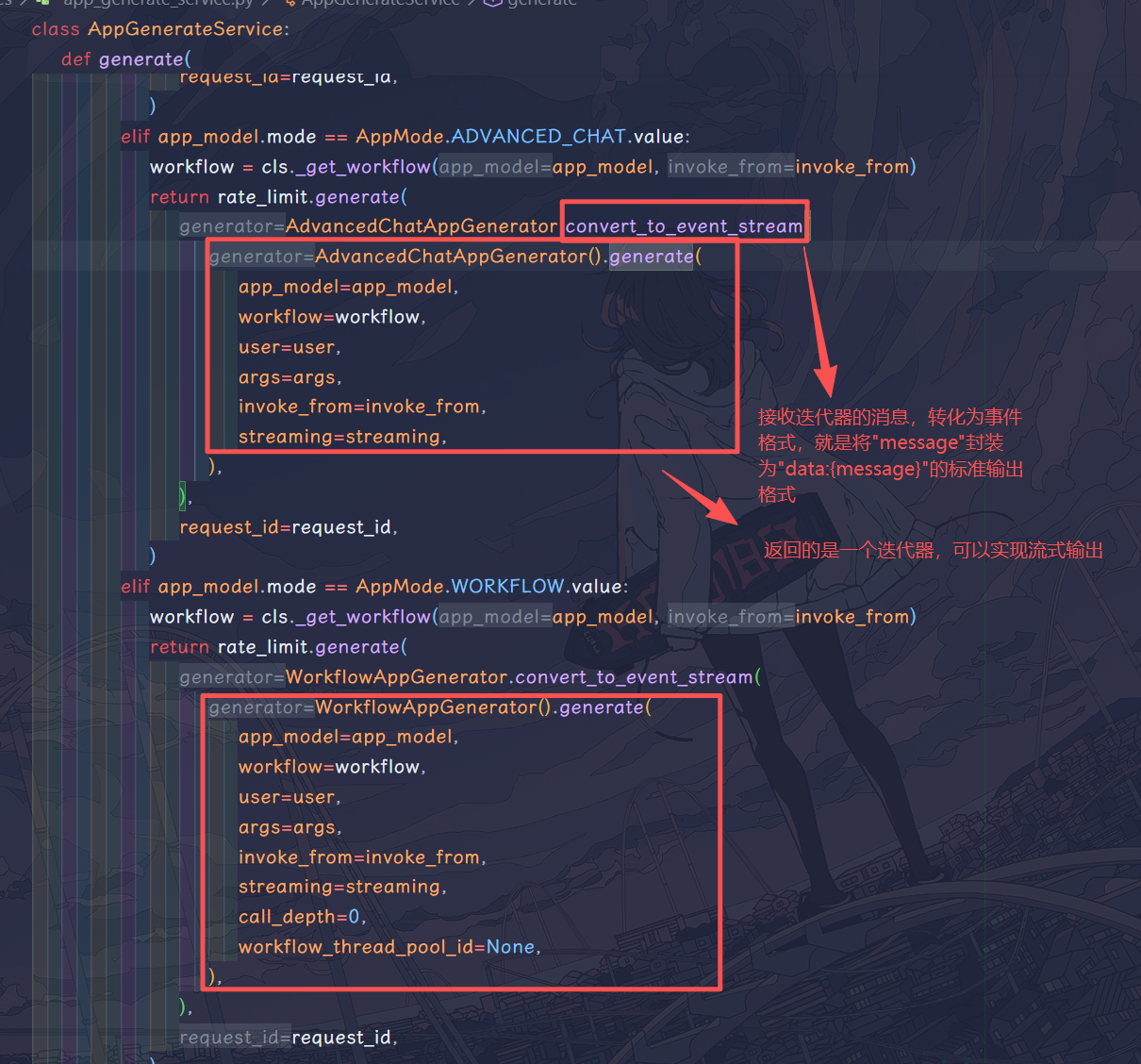
这里因为 chatflow 中可以添加直接回复节点实现流式输出,而 workflow 原生不支持,所以下面重点研究AdvancedChatAppGenerator().generate方法。现在先用伪代码梳理一下源码的大致结构:
1 | `AppGenerateService.generate() |
流程的话比较复杂,我用 Excalidraw 画了一个简单的图方便理解。个人感觉 WorkflowAppRunner -> WorkflowEntry -> GraphEngine 这种层层封装的信息传递方式很像计网里 OSI 层的信息传递方式。那下面的话就按照从上到下的层次顺序逐层说明一下代码。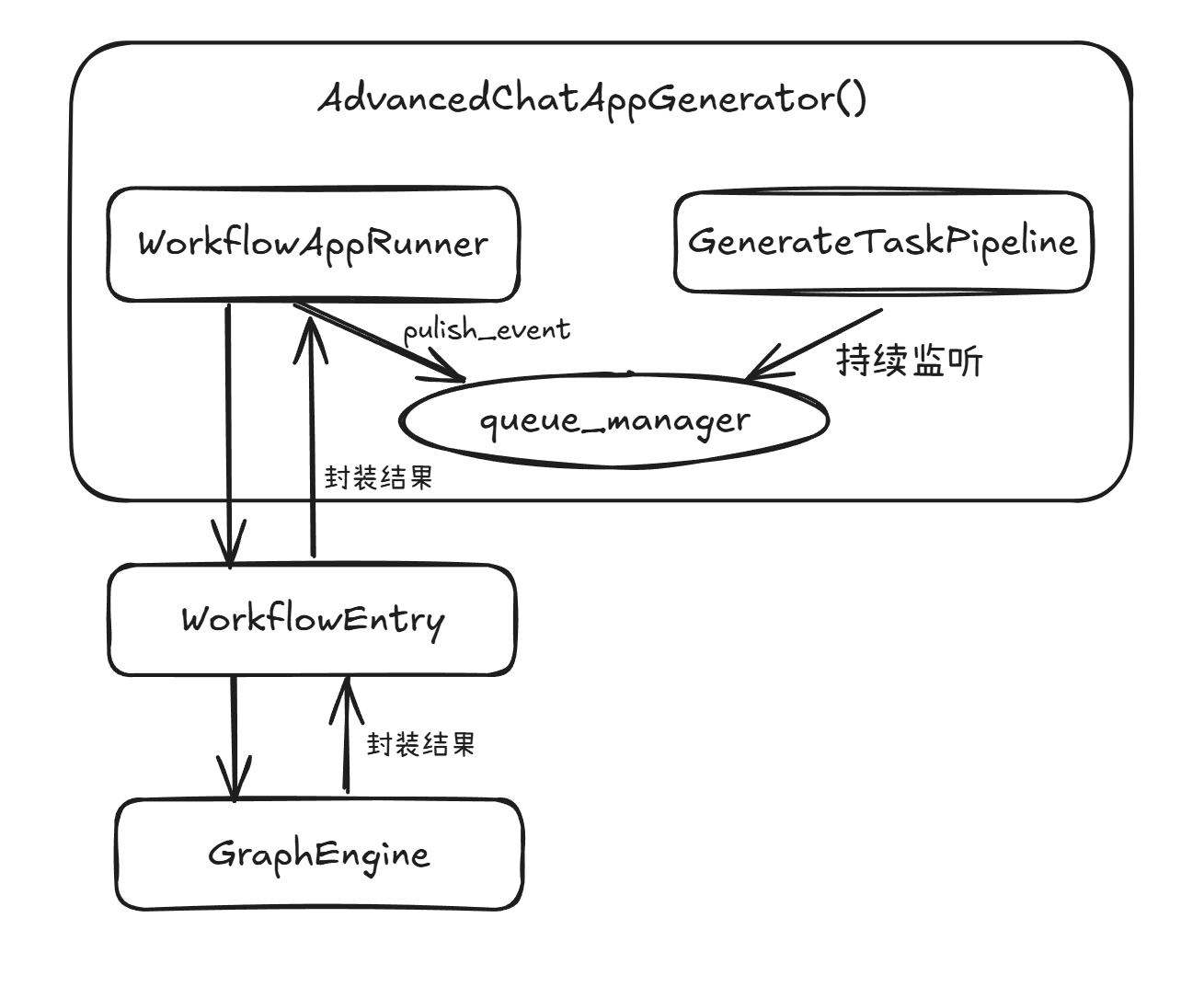
2. AdvancedChatAppGenerator 层 (request thread)
如果创建的应用是 chatflow,那么会在AppGenerateService.generate这一层会进入 AdvancedChatAppGenerator。这一层作为工作流启动的最高层,负责开启消息队列,记录会话信息等。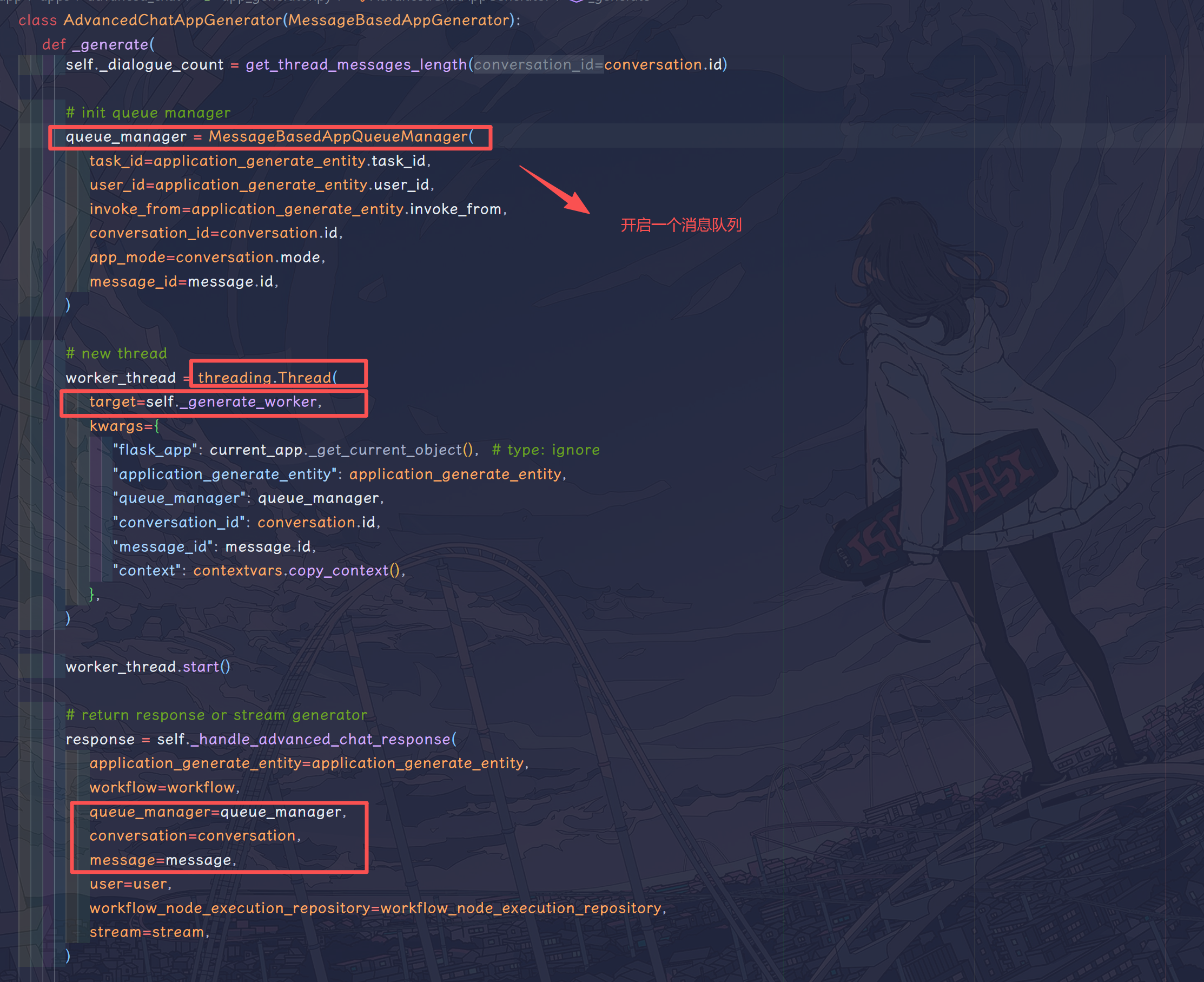
这里点开 MessageBasedAppQueueManager 的父类,可以发现这个队列是一直在持续监听的,当且仅当遇到错误 event 或者终止 event 才停止监听。这么做是为了在工作流执行报错的时候即使关闭监听任务,减少 CPU 资源的占用。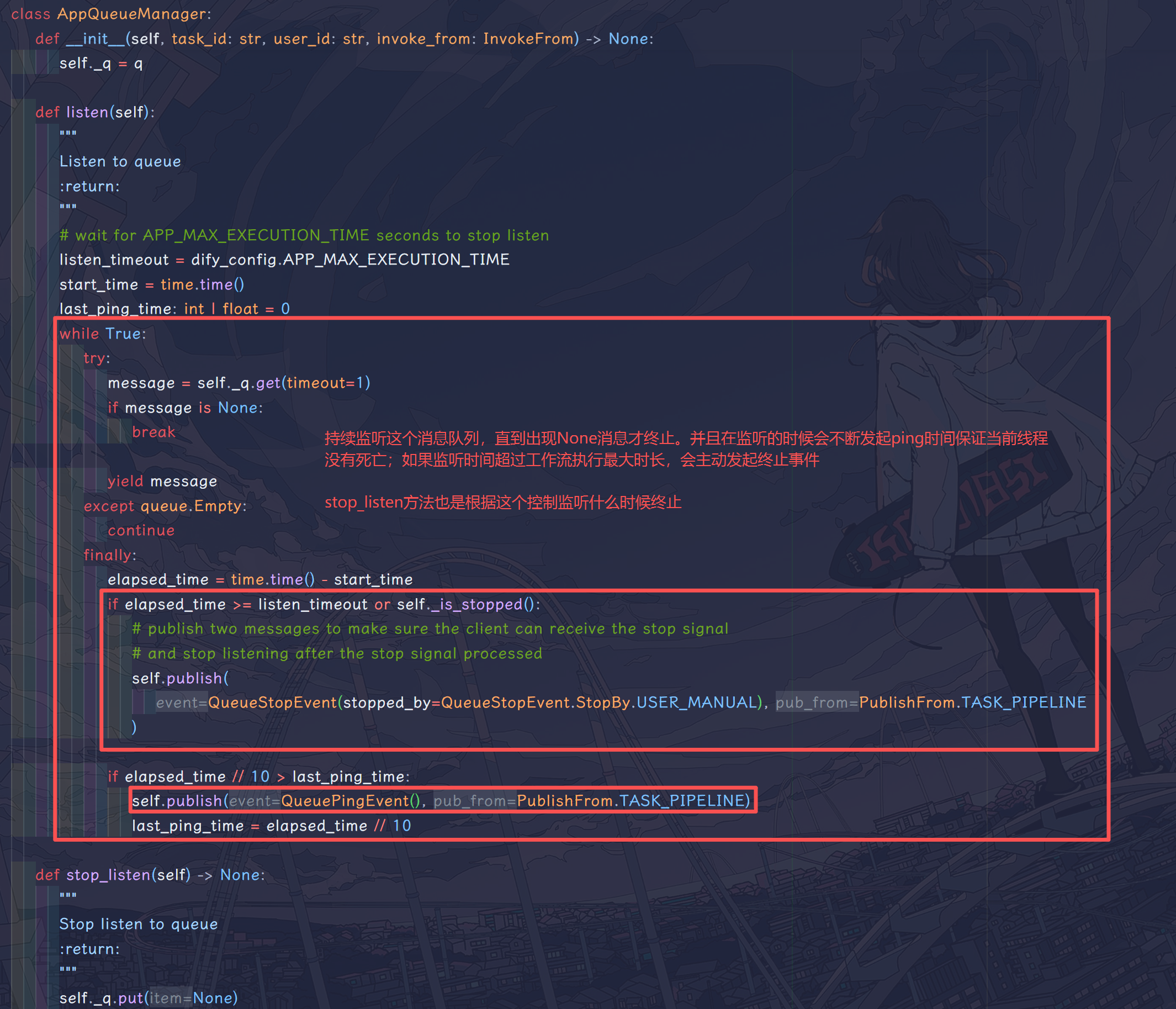
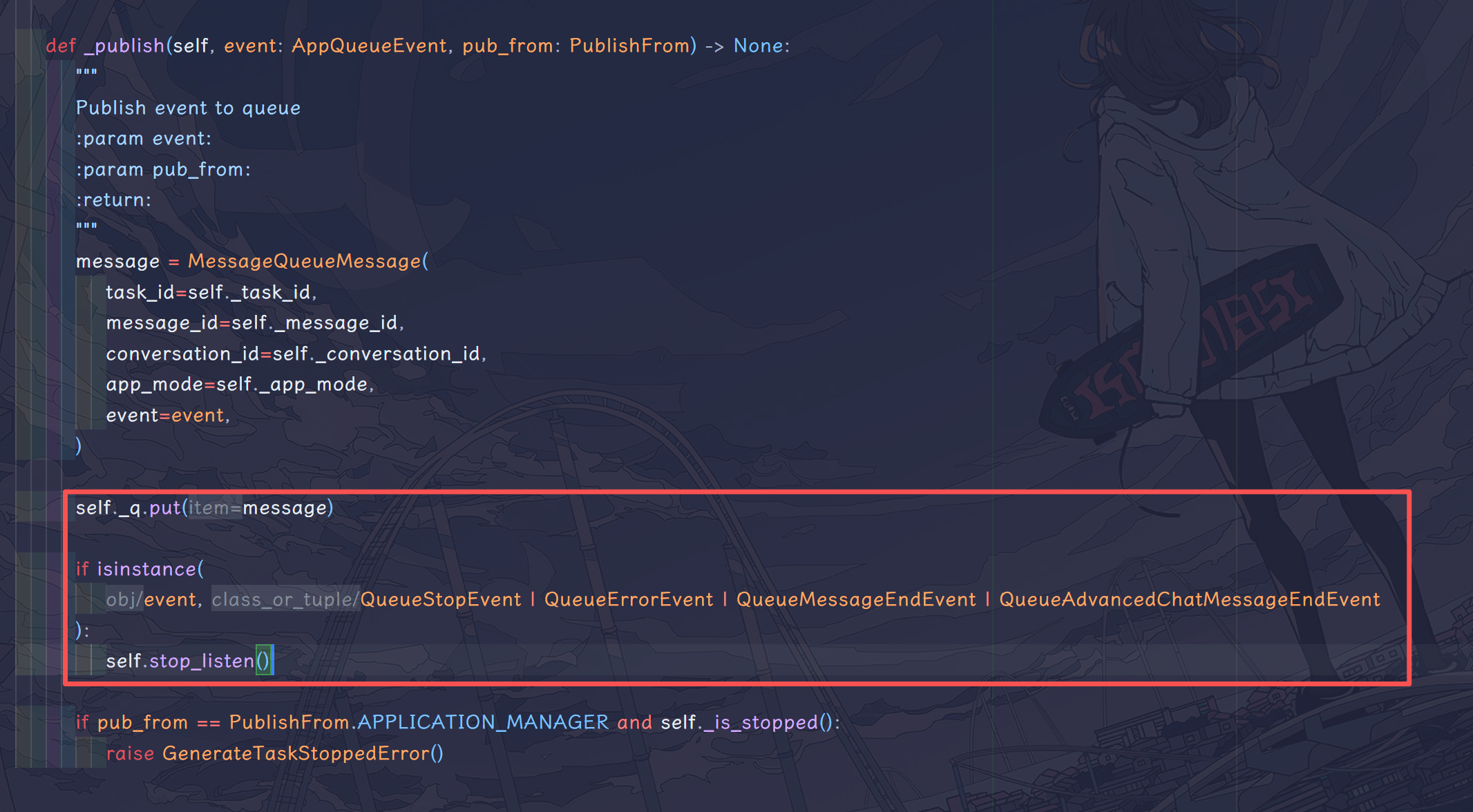
可以发现的是,消息队列监听任务消耗的是当前发起请求所占用的线程,app_generator 只额外开启了一个 generate_worker 线程用来执行工作流,并且向消息队列中发送信息。app_generator 在_handle_advanced_chat_response 方法中会不断监听这个消息队列,实际上,为了方便查看源码,可以在AdvancedChatAppGenerateTaskPipeline 的这个方法里打印日志信息: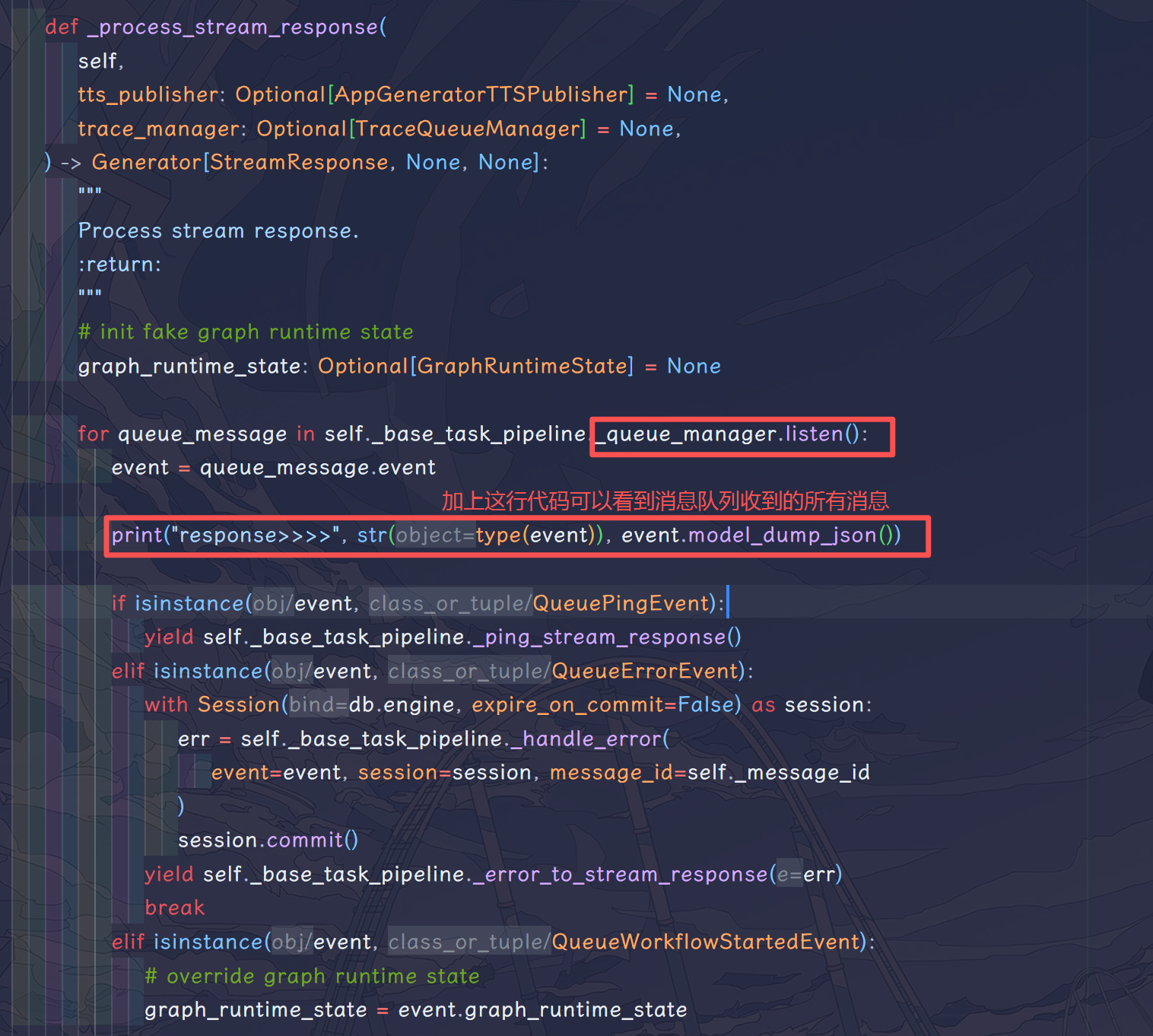
总结
- AdvancedChatAppGenerator 作为最高层,负责在工作流开始执行前做一些准备工作,比如开启新线程,记录日志到数据库,开启消息队列并开启监听消息队列等,本身不真正执行工作流;
- 消息队列持续监听占用的是收到 request 的接口线程,不是主线程,可以算是“主任务线程”;
- 消息队列收到工作流执行终止或者报错事件的时候会停止监听,避免查勇过多资源。
3.WorkflowAppRunner 层(new thread)
从这一层开始都是在开启的新线程中执行的了, WorkflowAppRunner 会先记录工作流执行时的 conv_id,变量信息等,并且在这一步会 加载 graph 的数据结构,解析工作流图中节点与边的关系,这是至关重要的一步,工作流的节点执行走向都依赖于此。
紧接着, WorkflowAppRunner 会创建一个 WorkflowEntry,然后就是上面说的消息封装再抛出了。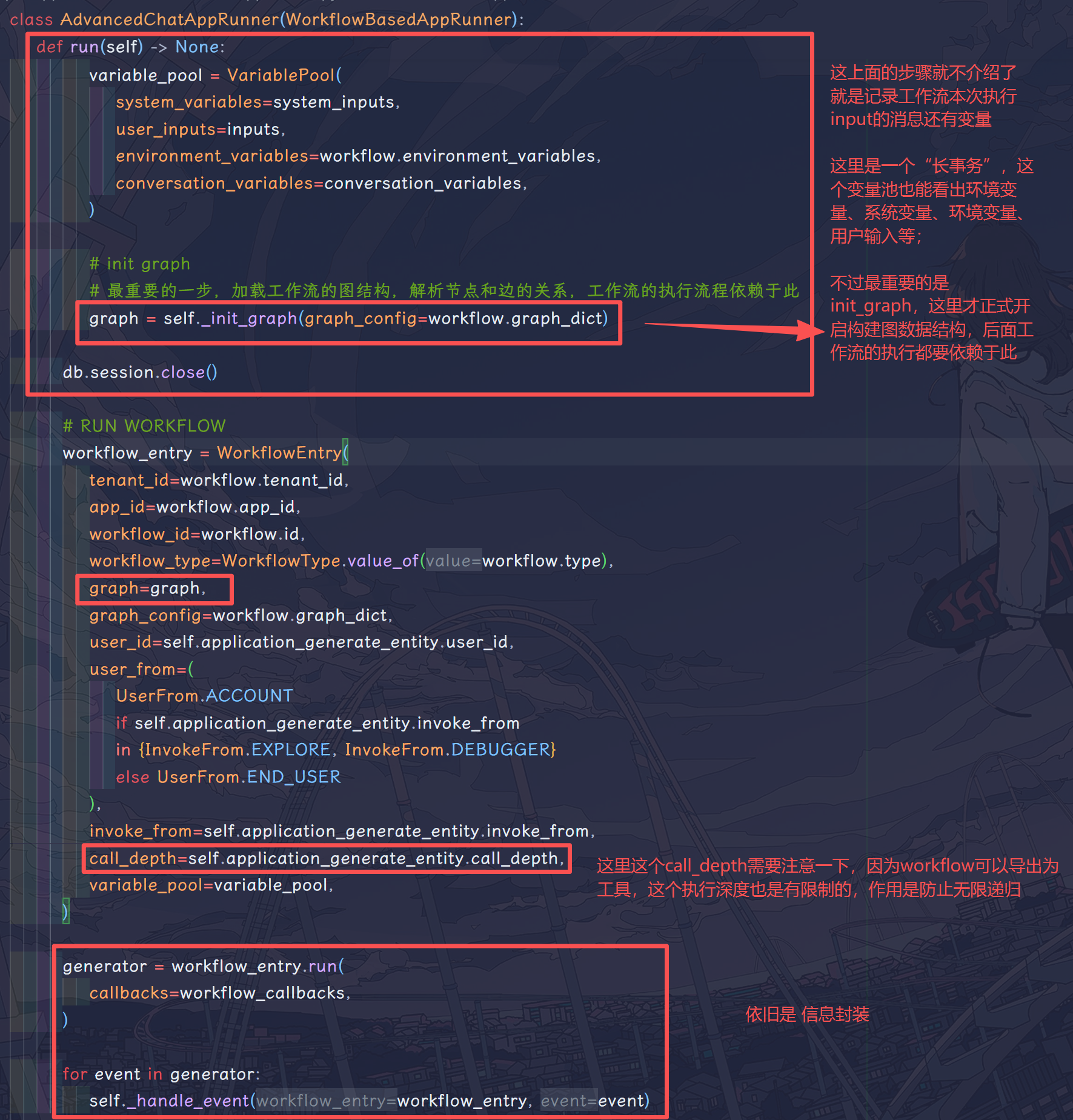
这一层的执行流程非常简约,最关键的那一步是init_graph,实际上这个方法来源于Graph.init。这一部分因为篇幅较长,会在后面的部分中详细介绍,,这里只需要知道init_graph负责将工作流的 json 配置文件加载成 graph,便于之后流程的进行和分析就可以了。
总结
WorkflowAppRunner是工作流 “预备执行” 的开始,负责工作流执行开始的 graph 解析工作和日志记录工作;- 最关键的地方就是 graph 的解析,后续工作流的执行全都依赖于此时的解析工作,包括 并行分支、直接回复节点等;
4. WorkflowEntry 层 (new thread)
我更愿意把这个类叫做 WorkflowInstance 类,其实这一层就是负责创建工作流执行实例,然后开始执行。上一层的WorkflowAppRunner完成 graph 解析之后,会将 graph 直接传递给 entry 的构造函数,这里会创建一个GraphEngine: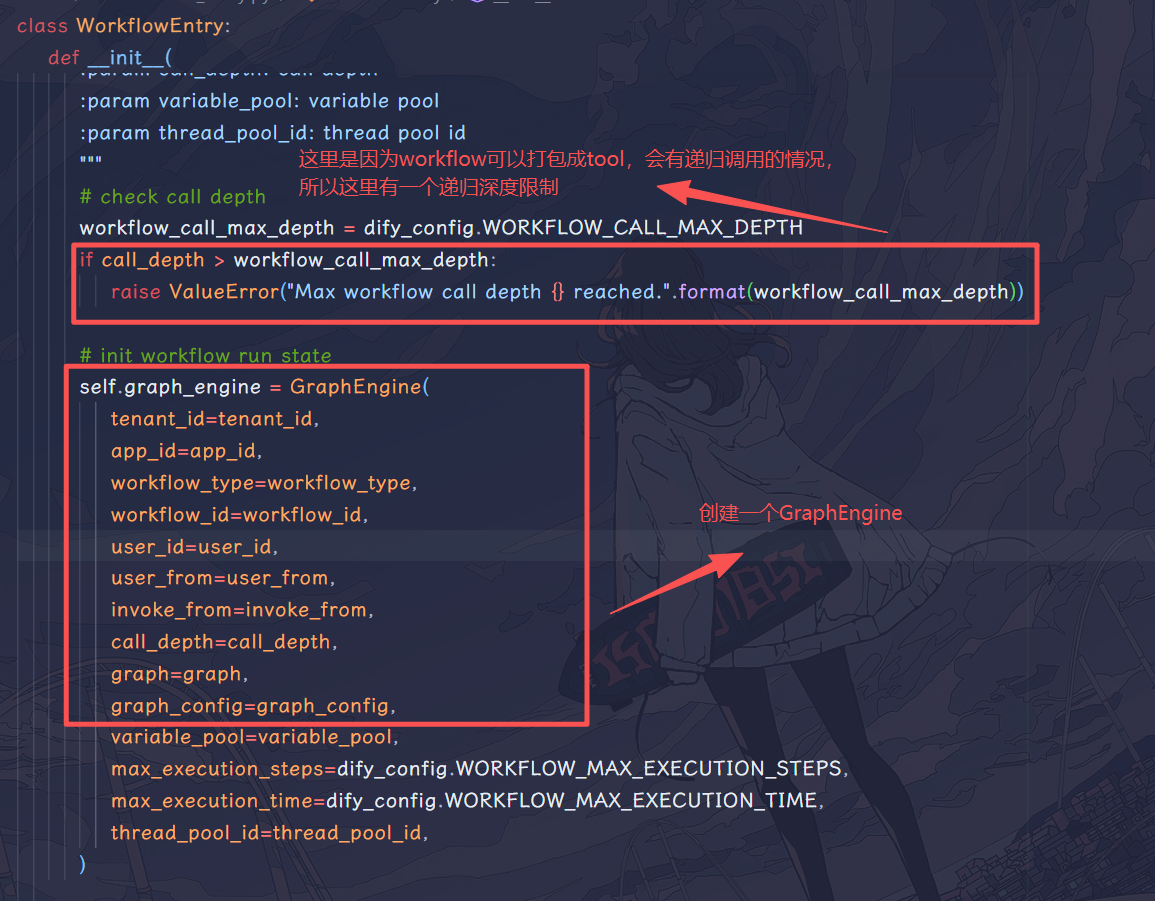
同样的,这里也是对信息再做一次封装,然后这里的 callback 应该是个后续扩展开发方向,因为现在的 callback 只有一个 WorkflowLoggingCallback,其作用目前只有记录日志,后续可能会有其他操作?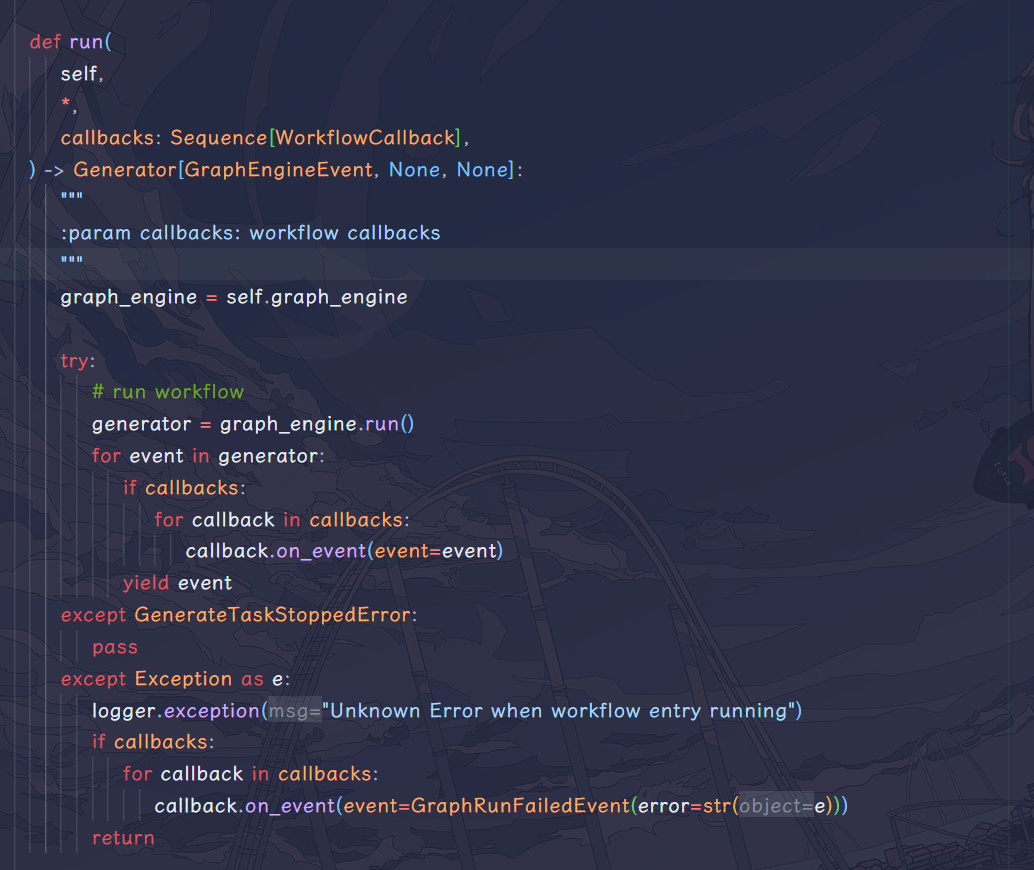
5. GraphEngine.run()层 (new thread)
现在终于到最底层了,到达这一层才是开始执行工作流节点的一层。对于 dify 中的工作流,底层原理是 DAG(有向无环图),执行过程中需要考虑LLM 节点的流式输出问题、并行分支的执行问题、执行过程中的变量上下文问题等。并且这里查看源码发现,dify 的开发者继承 ThreadPoolExecutor 创建了一个 GraphEngineThreadPool:
1 | class GraphEngineThreadPool(ThreadPoolExecutor): |
这个线程池后面会用来处理并行分支问题。下面还是直接看核心 run()方法: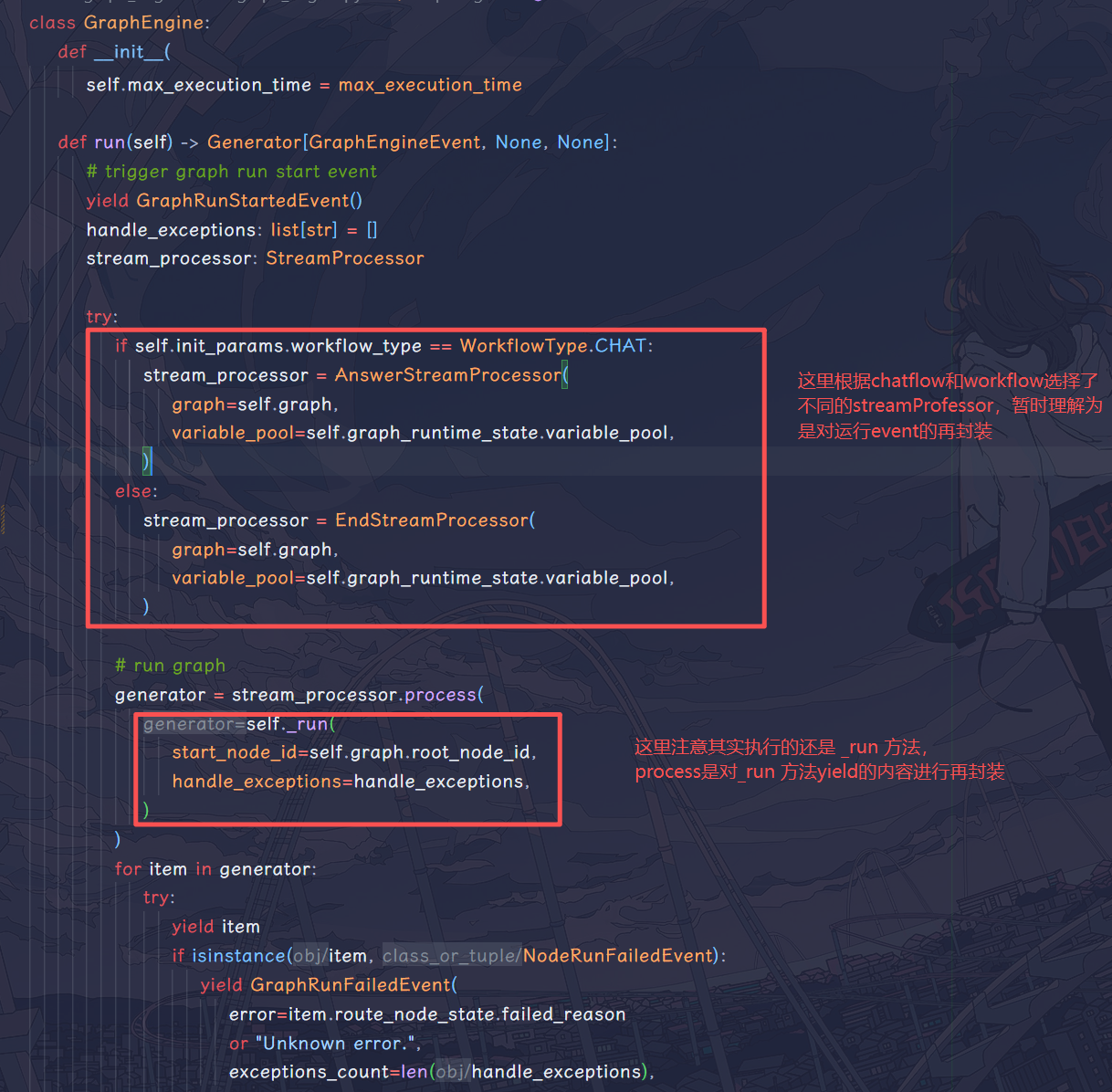
好的,下面就直接进入_run方法,可以发现这里开启了一个 while true 循环,并且会记录工作流执行步数和执行时间,如果超出限制会及时报错,防止工作流运行陷入死循环吞 CPU 资源。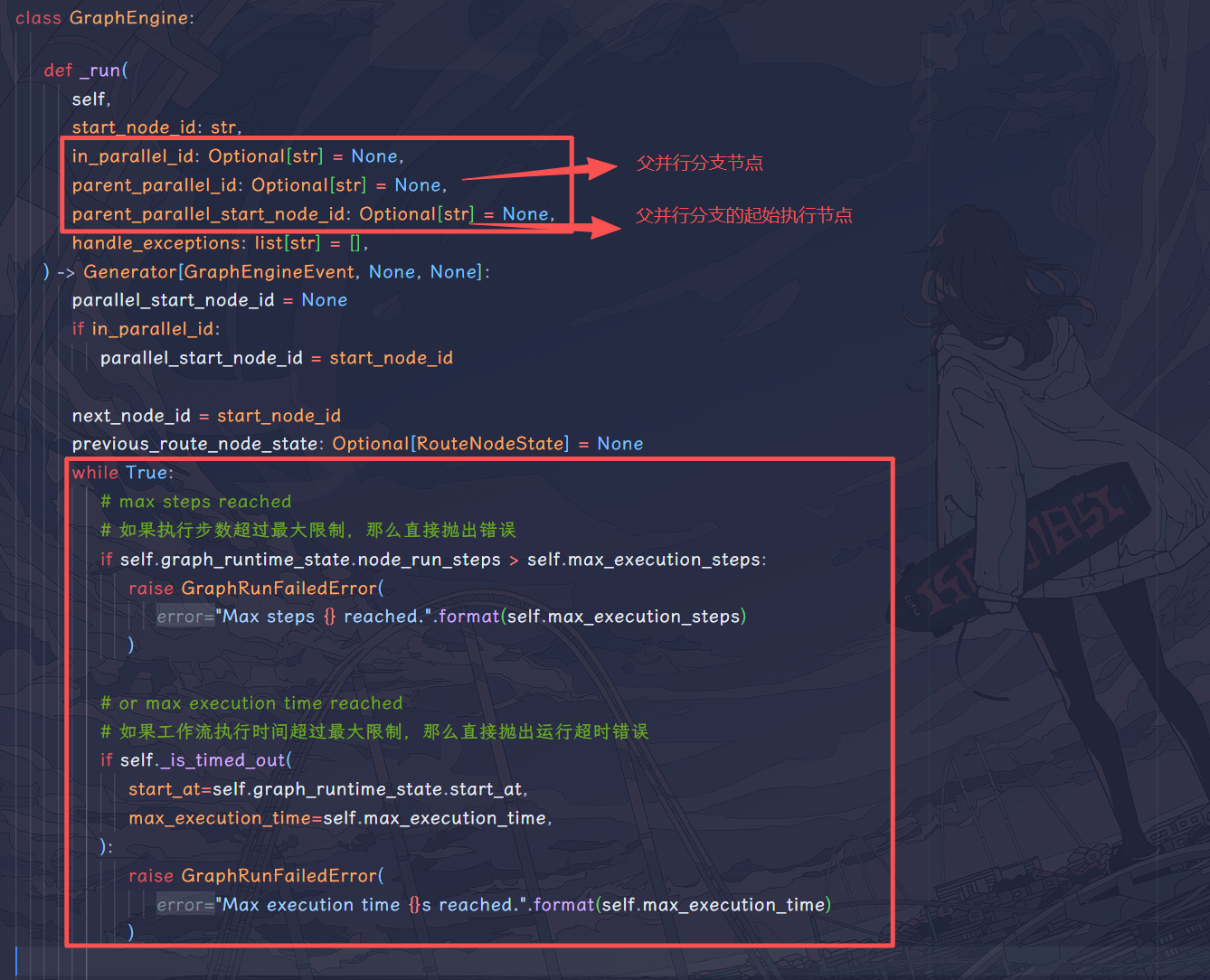
这里这个方法的代码的代码比较长,我在关键位置添加了对应的注释:
1 | def _run( |
简述一下执行流程,其实大概就是这样的:
- 开启一个 while true 循环,在循环中按照 graph 的节点顺序依次执行,如果运行超时或者超过最大步数立即终止循环;
- 运行单个节点返回的都是迭代器,原因是考虑到大模型节点是流式输出的;
- 单个节点执行完毕之后,会查找这个节点有多少出边,如果没有出边,则终止;如果仅有一条出边,则接着运行;如果有多条出边,首先判断有哪些出边满足 run_condition,并行运行这些有条件的出边;如果所有出边都没有 run_condition,那么直接并行运行所有出边;
- 并行处理时,在运行节点结尾判定,如果当前节点已经不在当前分支(分支有自己的 id)中,立即 break;
5.1 run_condition 长什么样子
有点想看一下这个 run_condition 长什么样子,这个应该是在条件分支节点之后添加上的。为了知晓答案,我用源码启动后端代码,前端和其他组件用 docker compose 启动,前端搭建的工作流如图: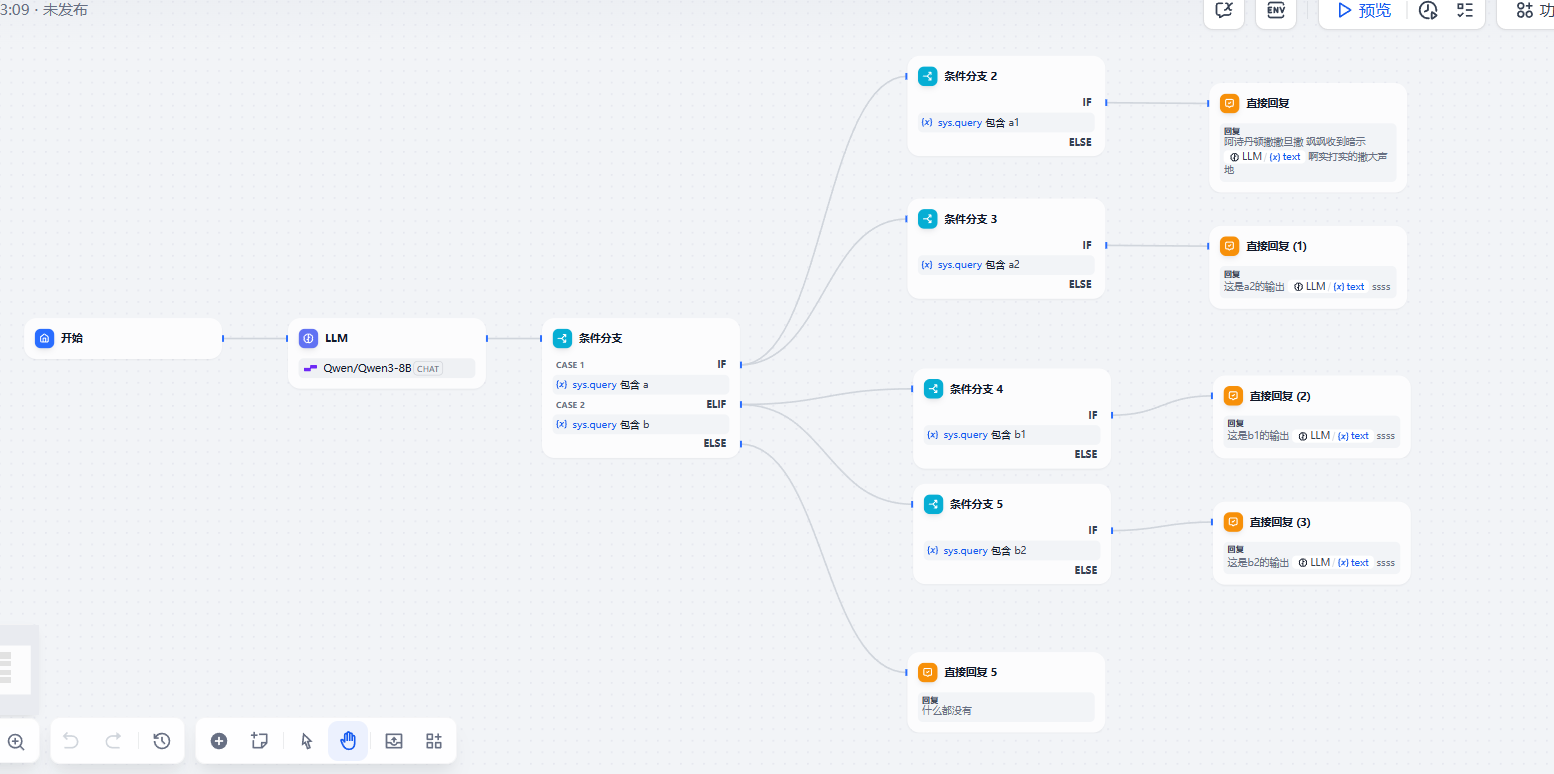
这里我在 IFElseNode 的源码位置打了断点,发现下列信息。对于条件分支这个节点,一共有两个 case_id,分别是 true、uuid(其实还有一个 false),这个就是分支的 id。
在 self.graph.edge_mapping 中,可以看到真正的 run_condition,其实和条件分支的 case_id 是绑定的: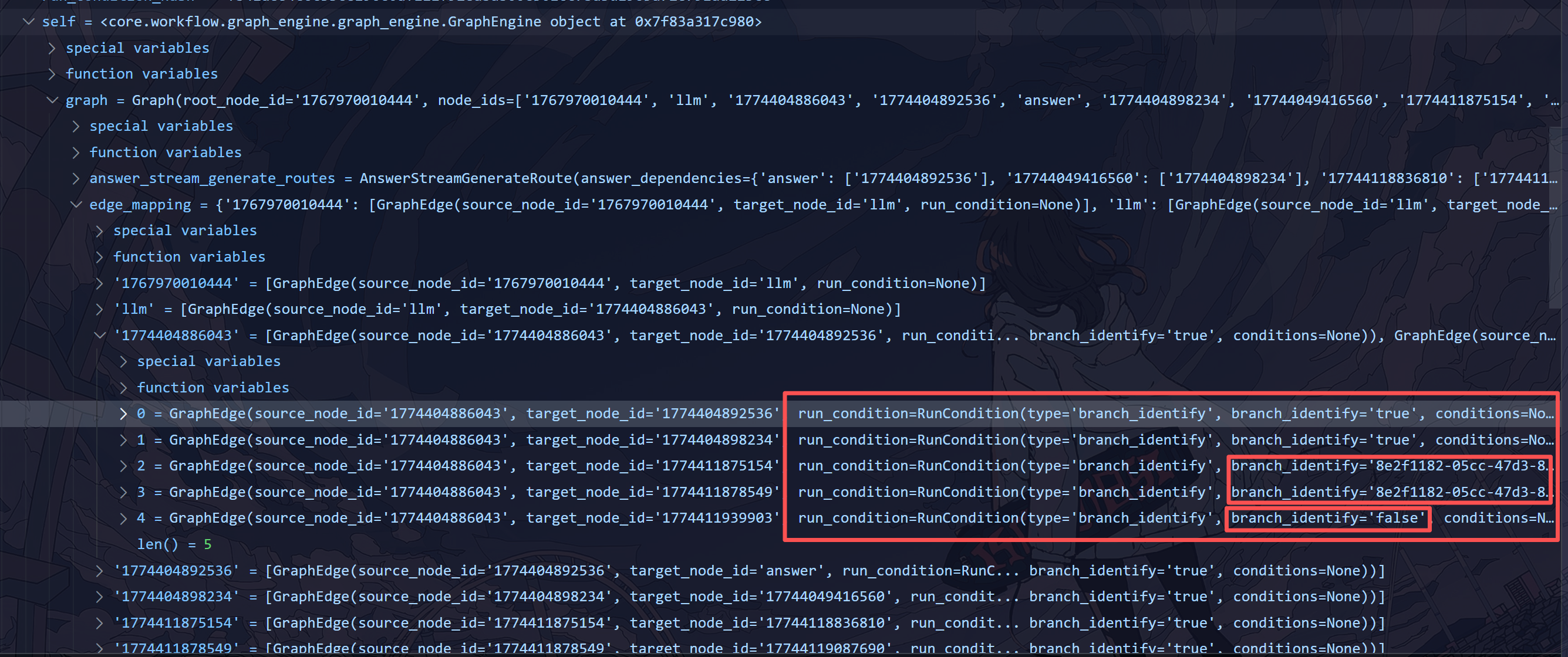
这里 IF-ELSE 节点结束之后,会在返回结果中记录 edge_source_handle 字段,条件判断器也是根据这个字段来判断是否满足执行条件的: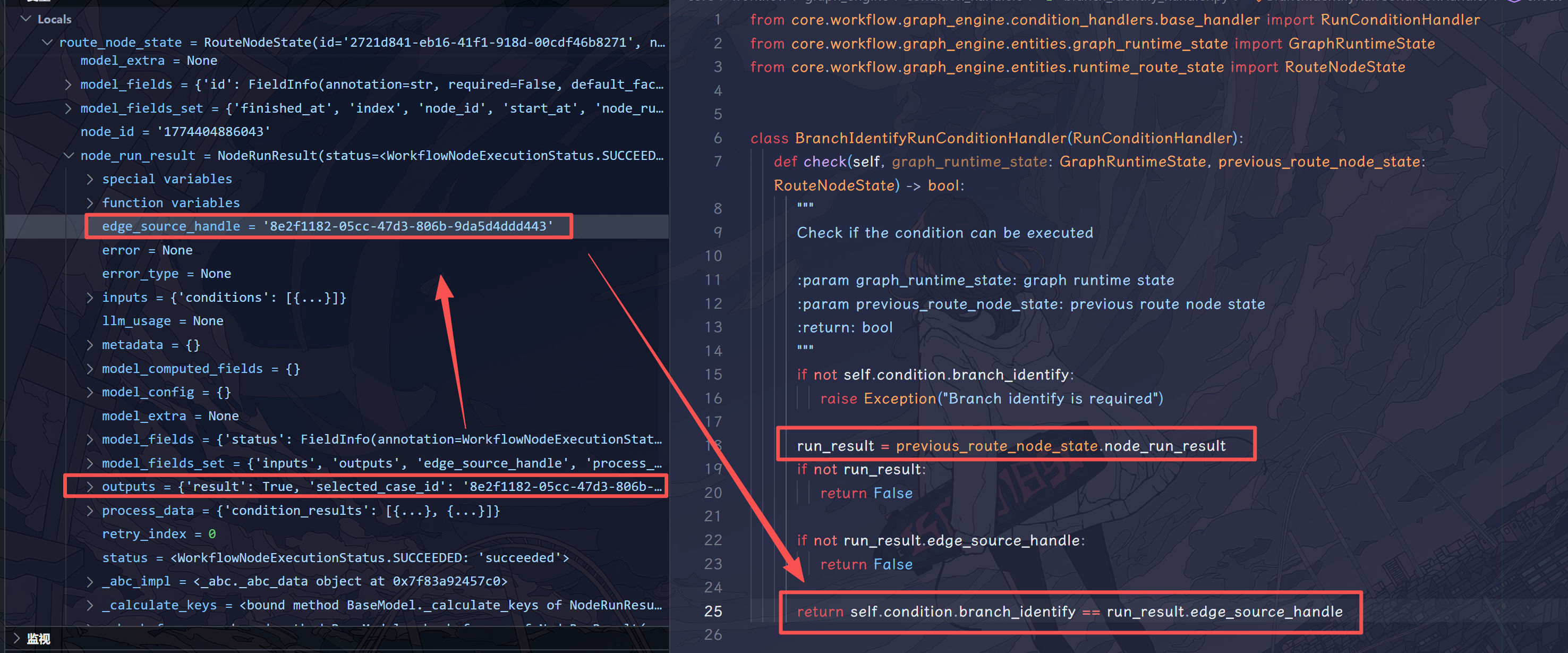
5.2 并行分支是怎么处理的?
这个我觉得是 dify 设计的一个小亮点,相关代码在这里。其实还是使用消息队列。将并行分支的任务放在线程池中并行运行,然后监听消息队列。每个线程在运行节点的时候都会检测,如果某个节点已经不在当前分支中,那么就立即 break:
1 | def _run_parallel_branches( |
Q:上面写到,并行分支运行的时候,会根据当前节点所属分支 id 与当前分支 id 是否匹配来判定,这个是怎么做到的?
A:在 graph.init 这一步做到的。这一步会解析节点与所有分支与子分支的从属关系,保存在map中,这个会在下一节中写。
- 标题: Dify 工作流引擎处理流程源码解析_01_基础结构篇
- 作者: fanz
- 创建于 : 2025-04-26 16:30:52
- 更新于 : 2026-03-26 16:31:26
- 链接: https://redefine.ohevan.com/tchzng/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。