
dify-RAG 探索笔记
1. dify的rag流程
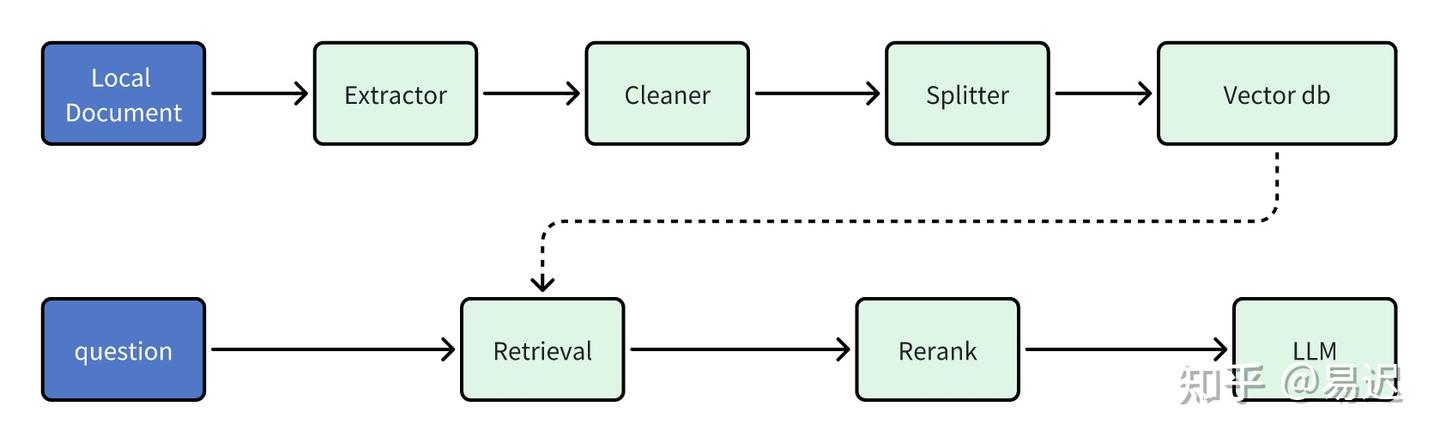
dify内置的rag比较简单,主要流程如下所示:
2.Extractor 文件内容提取器
提取文件的内容。对于doc、pdf、excel、csv、markdown等不同格式的文件,使用不同的方式提取文件内容。目前存在两类解析方案:
- 基于 Unstructured 的文件解析方案,支持接入付费的 Unstructured 服务,部分的格式解析只有付费版本才支持,比如 .ppt;
- 常规的 Dify 文件解析方案,基于开源库进行文件解析;
目前私有化部署时默认使用的是 Dify 文件解析方案,可以通过修改 .env 配置调整为 Unstructured 解析,但是使用 Unstructured 解析时需要配置对应的 Unstructured API 和 API Key,对应的配置如下所示:
1 | // 文件解析类型,可以设置为 dify 或 Unstructured |
2.1 word文档提取(只支持docx,不支持doc)
使用docx库解析word文档,通过元素类型(if "image" in rel.target_ref)判断元素是否是图片,如果是图片会将该图片自动上传,使用 类似的格式替换掉原图片。
2.2 pdf文档提取(不能分离图片,甚至pdf有图片时读取到的是乱码内容)
dify对pdf提取做的很少,直接使用 pypdfium2 库提取pdf文档内容。
1 | import pypdfium2 # type: ignore |
但是pypdfium2库读取时并不能将pdf中的图片分离出去,我自己上传了一个含有图片的pdf到dify的知识库中发现在切片时会出现乱码: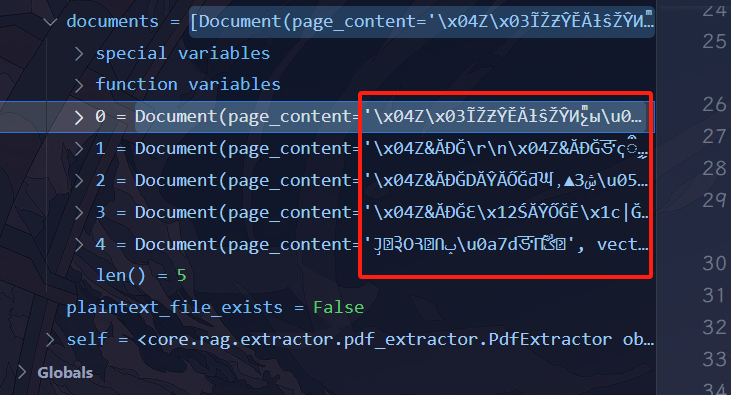
2.3 markdown文档提取
dify读取markdown的方式是按照标题进行区域划分,得到一个 {'标题','标题内容'}的map,再遍历这个map的key和value组成document数组,这里算是已经做了一步粗略的切片,不太清楚这样做的目的是什么。
2.4 html读取
使用BeautifulSoup库直接读取html内容。
2.5 csv和excel文件读取
使用openpyxl读取工作区,针对每个工作区使用pandas逐行读取数据。
3. Cleaner 清洗文件内容
这步功能较弱,只是利用固定的正则表达式进行清洗。目前支持的内容清洗主要是清理空格换行符以及清理 Email 和 Url,默认情况下仅会清理空格换行符。
4. Splitter:对文件内容进行切片
dify的切片方式比较简单,在之前的版本中主要使用了 EnhanceRecursiveCharacterTextSplitter 和 FixedRecursiveCharacterTextSplitter 两种。
老版本的dify中有一个 自动分段和清洗功能,对应的就是EnhanceRecursiveCharacterTextSplitter,但是在现在的版本中这个功能取消了,现在切片的时候都是需要用户手动配置分段标识符和分段最大长度等信息,使用的都是FixedRecursiveCharacterTextSplitter。
切片的原理是递归。简单来说就是先设定固定级别的分隔符(代码中设定的是separators=["\n\n", "。", ". ", " ", ""])。这里我们就按代码中设定的这个分隔符为例,文本内容会依次进行如下处理:
- 首先按照’\n\n’进行切片,对于片段长度小于限制的块保存到list中,片段长度较大的块进入下一轮递归;
- 这次按照’。'切片,片段长度较大的块进入下一轮递归;
- 这次按照’,'切片,片段长度较大的块进入下一轮递归;
- 这次按照空格’ '切片,一般到这里都是能返回要求的了,再下一轮递归就是按单个字符分割了;
其实这个分割原则还是比较简单的,基本就是逐段拆分-整句拆分-逗号拆分(断句拆分)-空格拆分这个流程。
- 标题: dify-RAG 探索笔记
- 作者: fanz
- 创建于 : 2025-04-24 18:00:37
- 更新于 : 2025-06-18 23:24:05
- 链接: https://redefine.ohevan.com/sv9w11/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。