
Dify 工作流引擎处理流程源码解析_02_Graph篇
在上一小节简单解析了一下 dify 工作流引擎处理过程中WorkflowAppRunner -> WorkflowEntry -> GraphEngine 这几层的处理过程。然后上一节说到 WorkflowAppRunner 会先根据配置文件解析出工作流的图数据结构,用以后续的执行,这一小节就详细介绍一下这个部分。我们重点讲Graph.init 这个部分,然后由于这个部分比较复杂,代码量比较多,这里挑其中几个关键部分加以说明。
首先还是使用邻接表法建立图,节点和边的信息都是保存在 edge_config 里的,这是一个 json 文件。当然这里值得注意的是 edge_mapping 是使用邻接表法建立正向图,而 reverse_edge_mapping 则是建立反向图,可以用于回溯。比较关键的部分是下面的_recursively_add_parallels 和GeneratorRouter.init方法。下面逐一介绍一下这两个部分。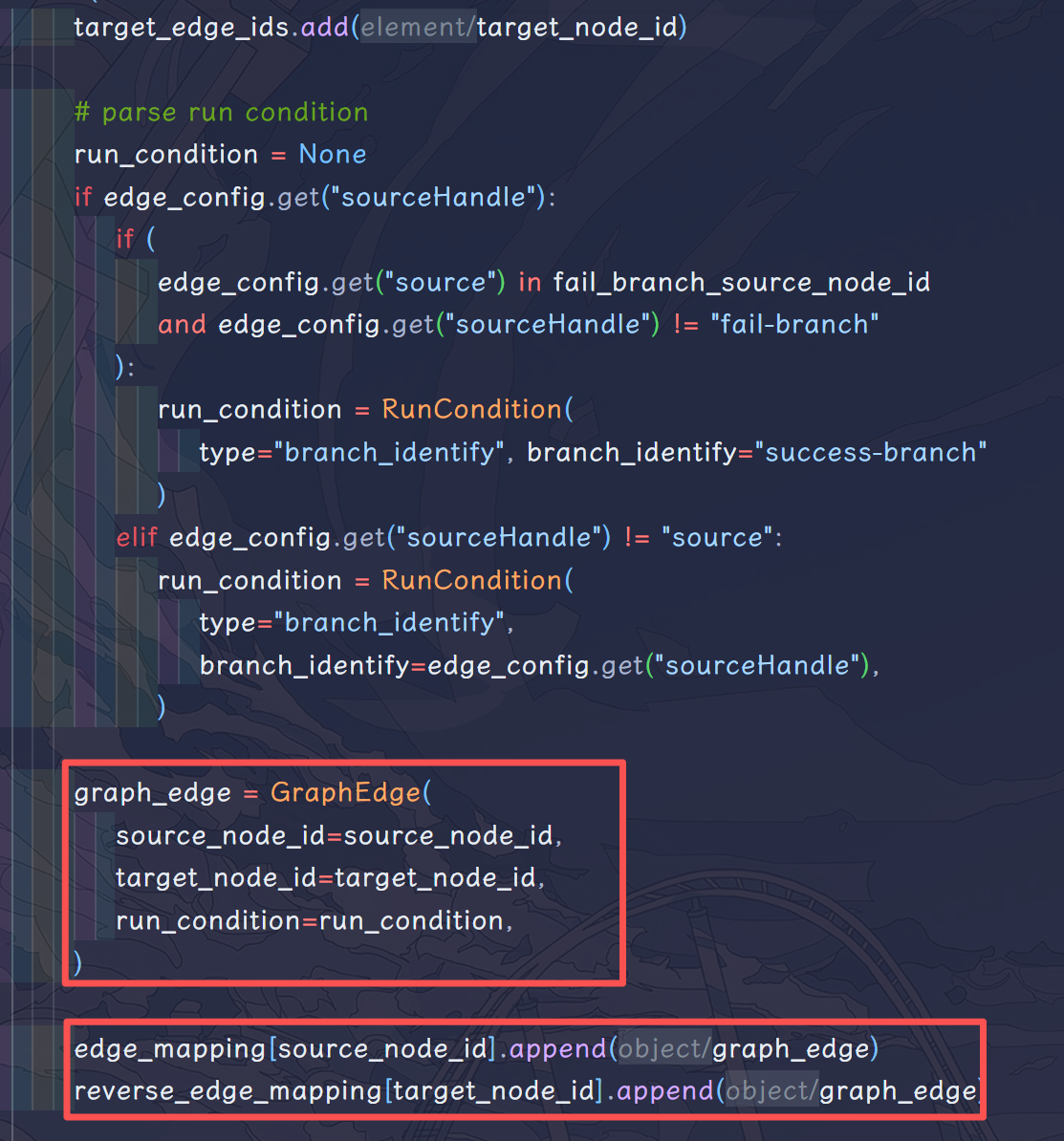

1. recursively_add_parallels
这个方法的作用直译过来就是 递归添加并行分支,其实本质上使用的还是 DFS 算法,遵从以下顺序:
首先从
start_node出发,获取该节点的所有出边。如果出边数量大于 1,才进入并行分支判断。如果分支没有条件,放在 “default” 分组中;反之则按照 run_condition 进行分组。每个分组内都是并行分支;然后我们遍历刚才的获得的那个分组 dict,对于每个分组,先获取属于该分支的所有节点(不含分支合并节点)。然后就是将这些 node_id 与并行分支 id 保存在 dict 中,这样 O(1)就可以判定节点属于哪个分支;

之后就是要找不属于当前分支的节点(个人觉得这里有点繁琐,因为其实在_fetch_all_node_ids_in_parallels 方法中已经大致可以判断出分支结束节点了)。这里的做法是,遍历属于这个分支的所有节点,然后只看“恰好只有一条出边”的节点,如果这个点就在父分支内 / 如果目标节点就是父分支的结束节点 / 如果没有父分支,而且目标节点不在任何并行分支内(说明目标节点在当前分支外部),那个这个节点肯定在并行分支之外;
如果“不属于当前分支的节点”只有 1 个,那么它就是当前分支的结束节点;
当前点遍历完毕,继续递归当前点的所有出边节点,循环往复;
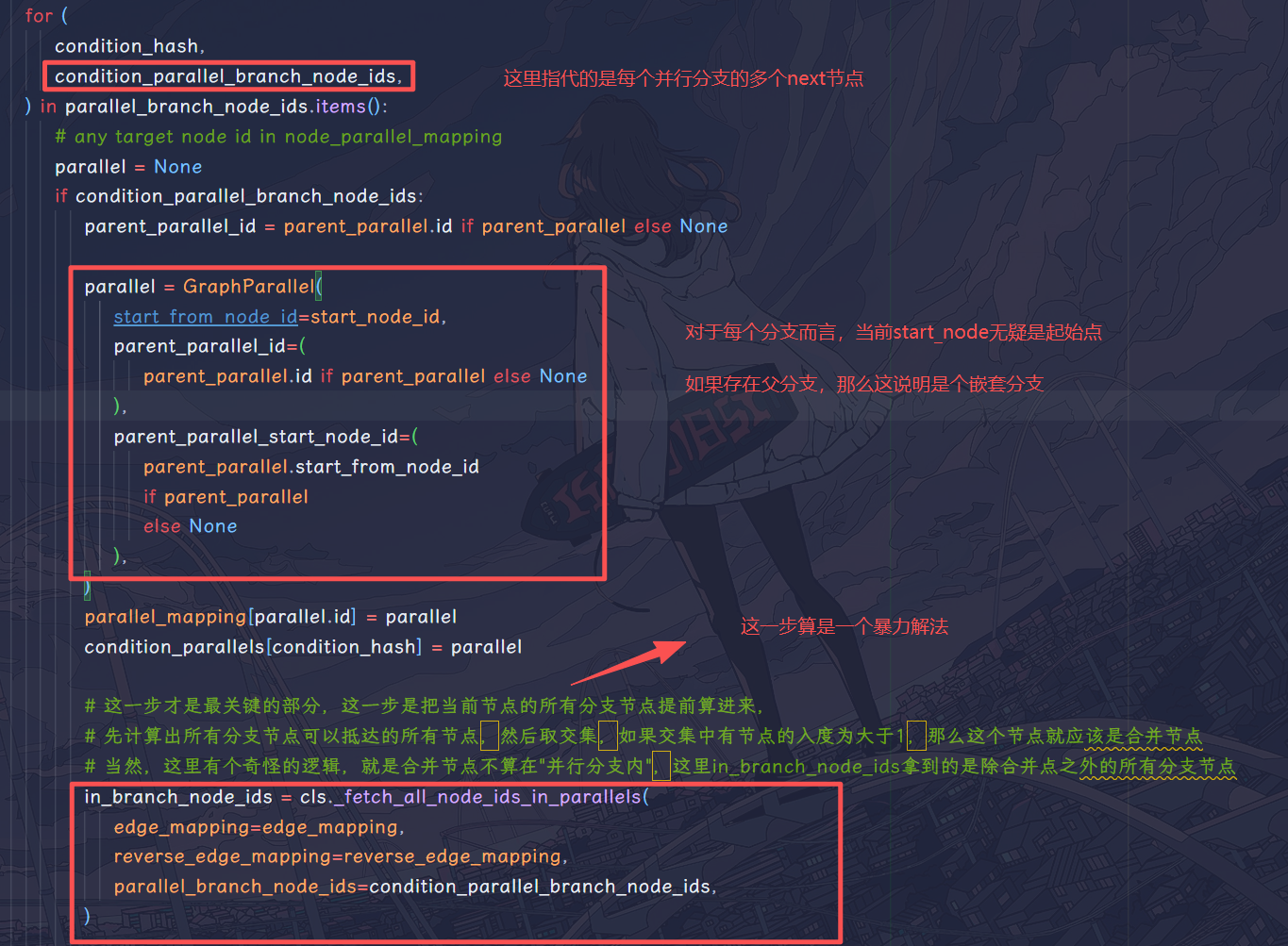
参考示例
上面这段流程看的肯定很懵,这里给出示例:
1 | ┌──(ok)──▶ B ───────────────┐ |
处理 A 的出边分组
condition_edge_mappings = {ok:[A->B,A->C], fail:[A->X]}- 只对
ok组建并行:P1(start=A, parent=None)
计算 P1 的分支内节点
in_branch_node_ids ≈ {B:[B], C:[C,D,E]}(合流点 F 不算“分支内”)parallel_node_ids = [B,C,D,E]node_parallel_mapping写入这 4 个节点属于P1
反推 P1 的出口
- 扫单出边节点:
B->F, D->F, E->F都跳出并行 outside_parallel_target_node_ids = {F}- 唯一候选成立:
P1.end_to_node_id = F
- 扫单出边节点:
递归到 C,生成子并行
C有两条边C->D, C->E,建P2(start=C, parent=P1)parallel_node_ids(P2) = [D,E]node_parallel_mapping[D/E]更新为P2(内层覆盖外层),P1为P2的父分支
反推 P2 的出口
- 候选跳出点:
D->F, E->F - 因为
F == P1.end_to_node_id,作用域合法 outside_parallel_target_node_ids = {F},最终P2.end_to_node_id = F
- 候选跳出点:
所以对于 ok 这个 run_condition 一共有两个分支P1、P2,其中P1为P2的父分支,他们的结束节点都是 F。
2. AnswerStreamGeneratorRouter.init
AnswerStreamGeneratorRouter.init 和 EndStreamGeneratorRouter.init的原理差不多,这里只介绍其中之一——AnswerStreamGeneratorRouter。
其实代码量还是不大的,可以看到首先就是找到工作流中的所有"直接回复"节点,然后解析出这个"直接回复"节点中的变量块与文本块(在AnswerStreamProcessor中有很大作用)。然后解析出每个"直接回复"节点的上游节点:
1 | class AnswerStreamGeneratorRouter: |
这里值得注意的是在_recursive_fetch_answer_dependencies方法里,下面这段代码比较重要:
1 | if ( |
我们以下面这个工作流为例: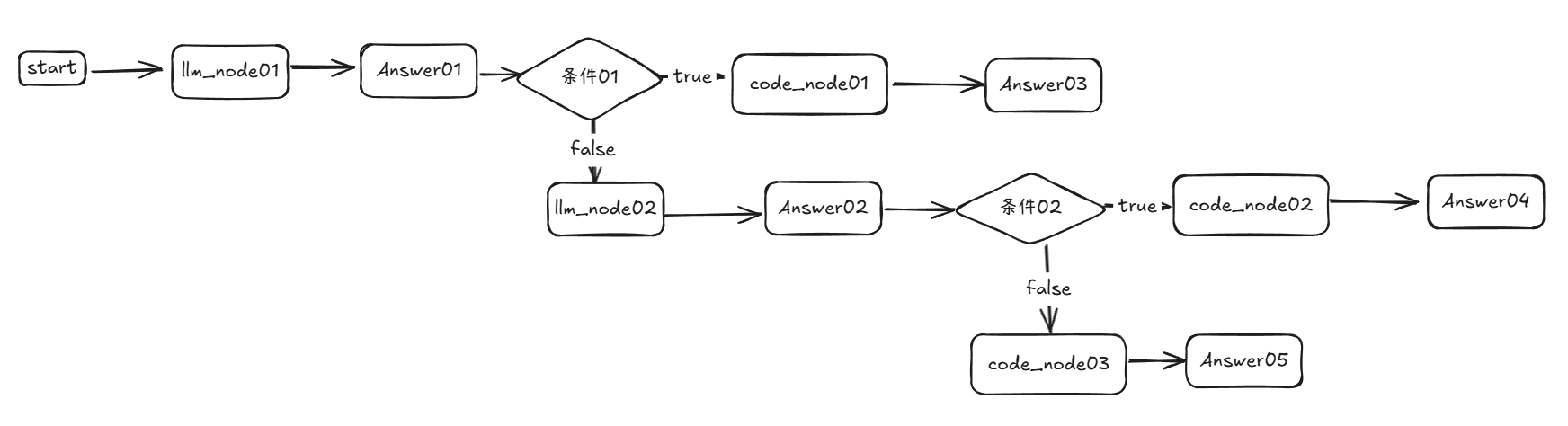
这里 条件 02 在 Answer04 和 Answer05 的上游节点中,从 Answer04 和 Answer05 直接获取上游节点的话,条件 02 的上游节点会重复写入这两个节点的 map 中。这里根据上面的算法,从 Answer04 和 Answer05 回溯获取上游节点时到 条件02节点就会 break。这么一来,Answer04 的上游节点为code_node02,条件02,Answer05 的上游节点为code_node03,条件02。以此类推,最终直接回复节点与上游节点的对应关系如图所示:
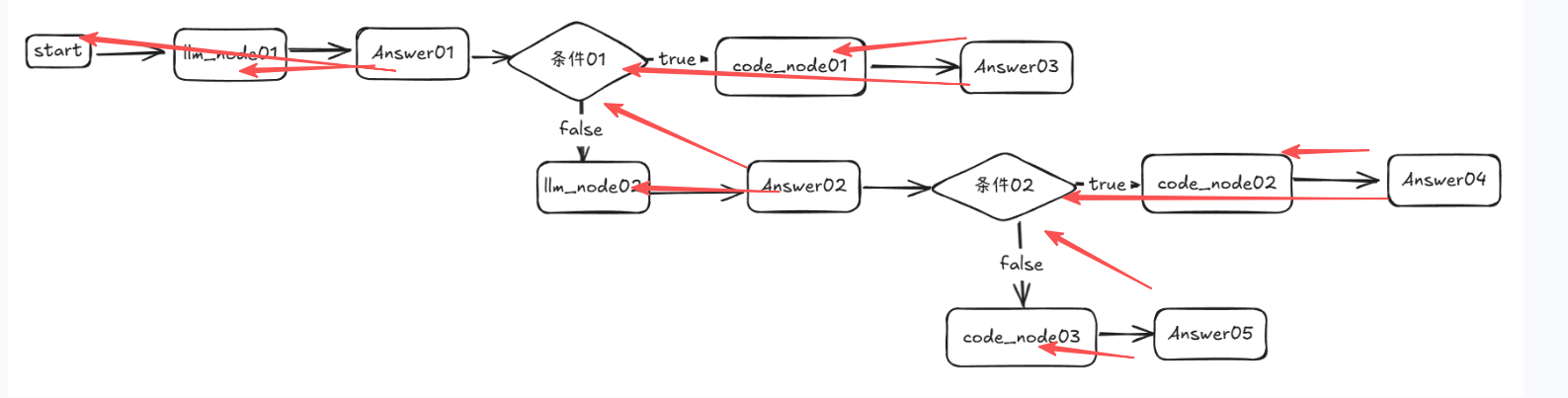
Q:为什么需要获取上游节点?并且为什么需要 break?
A:因为按照 dify 的逻辑,每个节点执行结束之后,应该立即检测其后是否有"直接回复"节点使用其输出信息。获取到上游节点之后其实是反向使用的,就是 根据当前 node 找最近的"直接回复节点",运行结束就赶紧检查"直接回复节点的情况"。
3. run_parallel 完整处理流程
综合上述信息,以下面的图为例,我们再来看一下上一节中运行并行分支的具体流程:
1 | START ──┬── NodeA ──┬── NodeC ──┐ |
预备数据(图初始化后,node_parallel_mapping 会记录每个节点对应的分支名,每个分支都有起始节点和结束节点):
1 | node_parallel_mapping = { |
Phase 1:主线程运行 START
1 | 主线程: _run(start_node_id="START", in_parallel_id=None) |
Phase 2:外层 _run_parallel_branches(主线程内)
1 | parallel_id = node_parallel_mapping["NodeA"] = "outer-p1" |
1 | 时间轴: |
Phase 3:Thread-B 的执行(简单,无嵌套)
1 | Thread-B: _run(start_node_id="NodeB", in_parallel_id="outer-p1") |
Phase 4:Thread-A 运行 NodeA,触发内层并行
1 | Thread-A: _run(start_node_id="NodeA", in_parallel_id="outer-p1") |
Phase 5:内层 _run_parallel_branches(在 Thread-A 内执行)
1 | parallel_id = node_parallel_mapping["NodeC"] = "inner-p2" |
1 | 嵌套队列关系: |
Phase 6:Thread-C 和 Thread-D 的执行
Thread-C:
1 | _run(start_node_id="NodeC", in_parallel_id="inner-p2", |
Thread-D: 同理,运行 NodeD 后在 SubMerge 处停止。
Phase 7:内层并行汇总,Thread-A 恢复
1 | Thread-A(阻塞在 q_inner.get): |
Thread-A 的 _run 收到 "SubMerge":
1 | for parallel_result in parallel_generator: |
Phase 8:Thread-A 继续运行 SubMerge
1 | Thread-A: next_node_id = "SubMerge" |
Phase 9:外层并行汇总,主线程恢复
1 | 主线程(阻塞在 q_outer.get): |
主线程的 _run 收到 "Merge":
1 | next_node_id = "Merge" |
完整时序图
1 | 主线程 Thread-A Thread-B Thread-C Thread-D |
核心设计要点小结
| 要点 | 体现 |
|---|---|
| 队列按层隔离 | 外层用 q_outer,内层用 q_inner,各自独立,不会混淆 |
| 事件逐层冒泡 | Thread-C/D → q_inner → Thread-A 转发 → q_outer → 主线程 |
停止信号靠 node_parallel_mapping | 每个线程到达不属于本 parallel_id 的节点时自动 break |
汇聚节点靠 end_to_node_id | 并行结束后 yield "SubMerge" / yield "Merge" 通知主循环继续 |
| 共享同一线程池 | 所有层的并行共用 GraphEngineThreadPool,受 max_submit_count 约束防止爆炸 |
- 标题: Dify 工作流引擎处理流程源码解析_02_Graph篇
- 作者: fanz
- 创建于 : 2025-04-30 17:41:36
- 更新于 : 2026-03-28 18:33:18
- 链接: https://redefine.ohevan.com/tcls9d/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。